Audio-Visual Emotion Recognition In Continuous Domain


Master Thesis, University of Hamburg (Informatik)
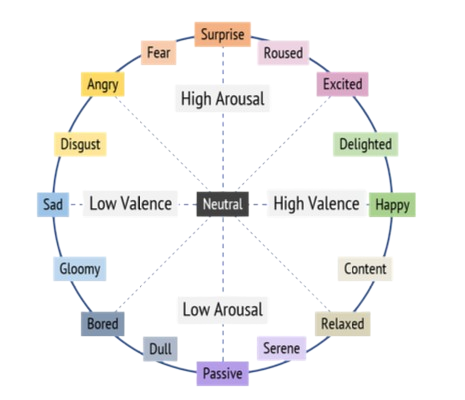
This research focuses on the complex challenge of Audio-Visual Emotion Recognition (AV-ER) within the continuous domain (Valence-Arousal space). Unlike traditional discrete emotion classification (e.g., Happy, Sad), continuous modeling allows for a more nuanced understanding of human affect by positioning emotions on a dimensional spectrum.
Methodology & Innovation
The core of the project lies in multi-modal representation learning. By leveraging both self-supervised and semi-supervised techniques, the framework achieves robust feature extraction even from large-scale unlabelled datasets.
1. Dual-Stream Representation Learning
- Speech (Audio): Implements and evaluates both contrastive and non-contrastive methodologies on unlabelled speech data (e.g., Tedlium v3). This ensures the model captures acoustic nuances that are typically lost in supervised training.
- Facial (Visual): Utilizes high-fidelity synthetic data (FaceSynthetics) to learn rich facial representations, ensuring the model is resilient to variations in lighting, pose, and occlusions.
2. Pseudo-Labelling Pipeline
One of the key contributions is an automated high-fidelity labelling pipeline. By strategically generating “pseudo-labels” for unlabelled data, the system significantly reduces the need for expensive manual annotation while increasing the training volume and subsequent accuracy on datasets like IEMOCAP.
🛠️ Technical Architecture
The project is built as a robust, production-ready Python package with a modular design:
- Framework: Developed using PyTorch for GPU-accelerated training and inference.
- Experiment Tracking: Full integration with Comet ML for real-time monitoring of loss curves, valence/arousal correlation (CCC), and hyper-parameter optimization.
- CLI-First Workflow: A comprehensive Command Line Interface that handles the entire pipeline—from dataset preparation and augmentation to multi-stage representation learning and final evaluation.
📊 Impact & Results
By integrating audio-visual streams through late-fusion and optimized attention mechanisms, the model demonstrates significant performance gains over single-modality baselines. The framework provides a scalable foundation for applications in Human-Robot Interaction, Empathetic AI, and Mental Health Monitoring, where understanding the subtle “shades” of emotion is critical.
